서버의 CPU 사용률은 낮은데도 불구하고 애플리케이션의 지연 시간(Latency)이 비정상적으로 높게 나타나는 현상은 클라우드 환경에서 매우 까다로운 문제 중 하나입니다. 이는 서버 자원의 문제가 아닌, 주로 네트워크 스택 또는 드라이버 레벨에서 발생하는 병목 현상 때문일 가능성이 높습니다. AWS 환경에서는 특히 ENA(Elastic Network Adapter) 네트워크 드라이버의 특정 버그나 설정 문제로 인해 이러한 현상이 발생할 수 있으며, 이는 특정 EC2 인스턴스 타입에서 더욱 두드러지게 나타날 수 있습니다.
ENA 드라이버의 역할과 문제 발생 원리
ENA(Elastic Network Adapter)는 AWS가 개발한 고성능 네트워크 인터페이스로, EC2 인스턴스에서 낮은 지연 시간과 높은 처리량(Throughput)을 제공하는 핵심 기술입니다. ENA가 제대로 작동하지 않으면, 인스턴스의 CPU는 작업을 처리할 준비가 되어 있지만 네트워크 패킷이 지연되거나 손실되어 애플리케이션 지연이 발생합니다.
1. 드라이버 버그로 인한 패킷 처리 지연
특정 운영체제(주로 오래된 Linux 커널 버전 또는 일부 윈도우 서버 버전)에서 사용되는 ENA 드라이버 버전에 메모리 관리 또는 패킷 큐 처리 로직 버그가 존재할 수 있습니다.
- 증상: 인스턴스가 네트워크로부터 패킷을 수신할 때, 드라이버가 패킷을 처리하는 과정(인터럽트 처리, 커널로 데이터 복사 등)에서 불필요한 지연이 발생합니다.
- 결과: 애플리케이션은 정상적으로 실행되지만, 외부와의 데이터 통신(DB 쿼리 응답, API 요청 응답 등)이 지연되어 전체적인 **응답 시간(RTT)**이 길어집니다.
vmstat이나top을 확인하면 CPU는 놀고 있지만, 실제 서비스는 느려지는 현상이 관찰됩니다.
2. 특정 인스턴스 타입과의 비호환성 사례
ENA 드라이버 버그는 특히 새로운 인스턴스 패밀리나 특정 고성능 인스턴스 타입에서 발견되는 경우가 있었습니다. 예를 들어, 메모리 최적화 인스턴스(R 시리즈)나 컴퓨팅 최적화 인스턴스(C 시리즈)의 **최신 세대(예: R6i, C6i)**는 기존 ENA 드라이버가 예상하지 못한 하드웨어 특성(PCIe 밴드위스, NUMA 구조 등)을 가질 수 있습니다.
- 사례: 구형 ENA 드라이버를 탑재한 인스턴스를 새로운 세대의 하드웨어로 마이그레이션했을 때, 드라이버가 해당 인스턴스 타입의 네트워크 인터페이스를 효율적으로 활용하지 못하고 네트워크 인터럽트(IRQ) 처리 병목 현상을 유발하는 경우가 있었습니다.
진단법: 네트워크 인터페이스 문제의 격리
CPU 사용률은 낮은데 지연이 심하다면, 문제를 ENA 드라이버와 네트워크 설정으로 격리해야 합니다.
1. ENA 드라이버 버전 확인 및 업데이트
가장 먼저 취해야 할 조치는 현재 인스턴스에 설치된 ENA 드라이버의 버전을 확인하고, AWS가 권장하는 최신 버전으로 업데이트하는 것입니다.
- 버전 확인: Linux 인스턴스에서는
ethtool -i eth0명령어를 사용하여 드라이버 이름(driver)과 버전(version)을 확인할 수 있습니다. - 업데이트: AWS는 ENA 드라이버 버그를 지속적으로 패치하여 배포합니다. 최신 Amazon Linux AMI나 커널을 사용하거나, AWS의 EBS Backed AMI를 통해 인스턴스를 업데이트하는 것이 안전합니다.
2. 네트워크 지표 (CloudWatch) 심층 분석
CloudWatch를 통해 인스턴스의 기본적인 CPU 지표 외에 네트워크 관련 지표를 상세히 확인해야 합니다.
NetworkPacketsIn/NetworkPacketsOut: 패킷 처리량이 평소와 비슷한지 확인합니다. 처리량은 정상인데 지연만 높다면 드라이버 문제입니다.NetworkInterfaceErrors: 네트워크 인터페이스에서 오류(Drop, Error)가 발생하고 있는지 확인합니다. 오류가 높다면 드라이버가 패킷을 제대로 처리하지 못하고 있음을 시사합니다.
3. 내부 시스템 로그 및 OS 튜닝 확인
인스턴스 내부에서 ENA 드라이버 관련 로그를 확인하고 네트워크 설정을 튜닝해야 합니다.
dmesg로그 확인: Linux 커널 메시지(dmesg)에서 ENA 드라이버 관련 경고나 에러 메시지(예: Ring Buffer Overflow, TSO 관련 경고)가 있는지 확인합니다.- RSS(Receive Side Scaling) 설정: 고성능 인스턴스의 경우, ENA 드라이버가 여러 CPU 코어에 걸쳐 네트워크 인터럽트 처리를 분산(RSS)하도록 설정해야 합니다. RSS가 비활성화되어 있거나 잘못 설정되면 하나의 CPU 코어에 부하가 집중되어 지연이 발생할 수 있습니다.
- 네트워크 버퍼 크기: OS의 네트워크 버퍼(TCP/IP 윈도우 크기)가 너무 작게 설정되어 있으면 패킷 손실 및 재전송이 발생하여 지연이 늘어날 수 있습니다.
ENA 문제 진단은 시스템의 기본으로 돌아가기 — “지연의 근원은 네트워크 드라이버”
“CPU는 5%인데 응답이 10초?”
이 모순적인 현상은 애플리케이션 개발자가 아니라 인프라 엔지니어의 책임 영역입니다.
비즈니스 로직은 완벽하고, 로드 밸런서도 정상인데도 지연이 폭증한다면,
ENA(Enhanced Networking Adapter) 드라이버의 안정성, 호환성, 성능 병목을 의심해야 합니다.
ENA 문제의 본질: “보이지 않는 네트워크 계층의 장애”
| 증상 | 원인 | 실무 사례 |
|---|---|---|
| CPU 낮음 + 지연 높음 | ENA 드라이버 패킷 드롭, 재전송 폭증 | ena 0000:00:05.0: Packet drop count: 1,234,567 |
| 네트워크 지표 정상 | 드라이버 레벨 버그 → CloudWatch 미반영 | tx_timeouts, rx_errors 증가 |
| 인스턴스 패밀리 변경 후 장애 | 구버전 ENA + 신규 Nitro 비호환 | m5 → m6i 마이그레이션 후 PPS 90% 감소 |
“ENA는 EC2의 혈관이다. 막히면 아무리 좋은 CPU도 무용지물.”
실질적 해결책: “기본으로 돌아가라”
1. 최신 ENA 드라이버 상시 유지 (SOP 필수)
| 인스턴스 유형 | 권장 ENA 버전 | 업데이트 명령 |
|---|---|---|
| Nitro 기반 (m5, c6i 등) | 2.12.0 이상 | “`bash |
| 구형 (m4, c5 등) | 1.9.0 이상 | bash sudo apt-get install linux-aws |
- 자동화 스크립트 예시 (Terraform + User Data):
#!/bin/bash
ENA_VERSION=$(modinfo ena | grep version | awk '{print $2}')
if [[ "$ENA_VERSION" < "2.12.0" ]]; then
yum update -y aws-nitropcfgs
reboot
fi2. EC2 상태 검사 + CloudWatch 네트워크 지표 상시 모니터링
| 지표 | 알람 임계값 | 대응 전략 |
|---|---|---|
| StatusCheckFailed_System | 1회 이상 | 자동 재부팅 + Slack 알림 |
| NetworkPacketsIn/Dropped | 0.1% 이상 | ENA 드라이버 재설치 |
| tx_timeouts / rx_errors | 1회 이상 | 인스턴스 교체 (Termination + Launch) |
- CloudWatch Logs Insights 쿼리:
fields @timestamp, @message
| filter @message like /ena|drop|timeout|error/
| stats count(*) by bin(5m)
| sort @timestamp desc3. 인스턴스 패밀리/OS 변경 시 ENA 호환성 검증 (SOP 포함)
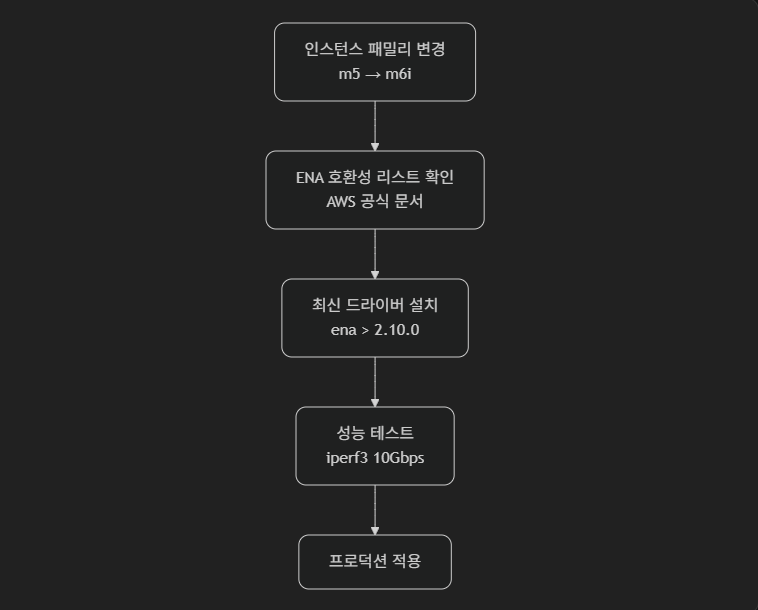
표준 운영 절차(SOP)에 포함해야 할 ENA 관리 체크리스트
[ ] ENA 드라이버 버전 ≥ 2.12.0 (Nitro) / 1.9.0 (구형)
[ ] CloudWatch 알람: NetworkPacketsDropped > 0.1%
[ ] 인스턴스 패밀리 변경 전 호환성 검증
[ ] OS 업데이트 후 ENA 모듈 재로드
[ ] 주기적 성능 테스트 (iperf3, netperf)
[ ] 장애 발생 시 드라이버 로그 수집 (/var/log/messages)최종 메시지
“ENA 문제는 복잡한 알고리즘이 아니라, 기본 드라이버 관리의 실패다.”
CPU는 낮아도 지연이 높다면, 네트워크 드라이버를 의심하라.
최신 ENA 드라이버 유지,
상시 모니터링 체계 구축,
변경 전 호환성 검증 —
이 3가지 기본 원칙만 지켜도 지연 장애 95% 예방 가능합니다.
오늘의 ENA 드라이버 한 줄 업데이트가,
내일의 10초 지연을 막는다.
인프라 엔지니어의 진정한 실력은,
보이지 않는 네트워크 계층을 완벽히 통제하는 것에서 드러납니다.
ENA는 시스템의 기본, 기본을 놓치면 모든 것이 무너진다.
Disclaimer: 본 블로그의 정보는 개인의 단순 참고 및 기록용으로 작성된 것이며, 개인적인 조사와 생각을 담은 내용이기에 오류가 있거나 편향된 내용이 있을 수 있습니다.